dimanche 28 mars 2010
Une architecture cluster a pour objectif d’assumer une charge fluctuante et d’assurer un service transparent aux pannes et aux maintenances. Les concepts sont :
ü Fail Over & High Availability Rendre transparent aux utilisateurs finaux les pannes de la plate-forme et les maintenances applicatives pour un service 24/7.
ü Load Balancing Capacité à répartir la charge utilisateur sur l’ensemble des ressources mise à disposition du cluster.
ü Scalability Capacité à modifier la capacité de la plate-forme afin de répondre à une variation de charge.
ü Centralization Centralisation de l’administration afin de faciliter les maintenances applicatives.
ü Migration Les ressources singleton peuvent être migré sur une instance valide en cas de panne de l’instance hébergeur.
ü Virtualization Compartimenter et maitriser les fluctuations de charge dynamiquement afin de mieux gérer les variations. Mieux répartir les clusters selon leurs charges pour mieux exploiter la plateforme machine.
Les grands principes étant de fragmenter le plus possible par paire les nœuds de façon a facilité les traitements internes (taille mémoire plus petite à gérer, nombre de threads internes plus nombreux pour l’infrastructure) et mieux géré les failover et failback (plus de nœuds disponibles pour assurer la surcharge lors de panne, failback meilleure répartition sur un retour à la normale).
Toutes les interfaces JEE (Servlet/JSP/EJB/JMS/JTA) et architectures (MAN/LAN/WAN) supporte par différent moyen et paramétrage le clustering.
Chaque Protocol implémente une interface associé au Cluster :
ü HTTP
ü RMI
ü JMS
ü JNDI
ü JDBC
Plusieurs architectures sont possibles :
ü LAN
ü MAN
ü WAN
ü Etat de vie (Heart Beat) Observer son voisin pour savoir s’il est toujours en vie.
ü Réplication (Fail Over) Répliquer les données utilisateurs sur une ressource distance.
ü Répartition (Load Balancing) Répartir la charge sur l’ensemble du cluster.
ü Extensibilité (Dynamic Liste) Gérer l’ajout de nœud dynamiquement.
Le heart beat peut être géré de deux façons différentes :
ü MULTICATS
ü UNICAST
Pour les autres échanges, c’est le mode point à point qui est utilisé.
· Principe : Le mode de dialogue multicast passe par un message Broadcast (type 4) pour la communication inter instance. L’avantage de ce mode est qu’il est robuste, mais propagé sur les autres réseaux (voir avec les experts système). Vérifier que l’adresse multicast du cluster n’est pas utilisée par d’autres composants afin d’éviter le conflit.

· Pour valider le bon fonctionnement réseau, vous pouvez passer le test suivant. Lancer la commande sur chaque machine avec la même adresse multicast et éventuellement le même port, mais avec un nom différent par machine (prendre par exemple le nom de la machine). Appliquer ce test instance arrêté, car celui-ci peut engendrer un trafic perturbant.
Lancer la commande simultanément sur les machines du cluster, et vérifier que sur chaque machine, on reçoit bien les trames de la machine voisine en observant l’apparition du nom passé en paramètre.
java utils.MulticastTest –n -a
-n | Nom |
-a | adresse |
-p | port |
-t | timeout |
-s | interval d’envoi (second) |
Ex :
D:\bea\wlserver6.0sp1\config\CLUSTER> java utils.MulticastTest –n Server1 -a 224.0.0.0
***** WARNING ***** WARNING ***** WARN
Do NOT use the same multicast address
Starting test. Hit any key to abort
Using multicast address 224.0.0.0:7001
Will send messages under the name Serv
Will print warning every 600 seconds i
I (Server1) sent messa
Received message 2 from Server1
I (Server1) sent messa
Received message 3 from Server1
I (Server1) sent messa
Received message 4 from Server1
I (Server1) sent messa
D:\bea\wlserver6.0sp1\config\CLUSTER>
En cas de problème, c’est qu’il n’y a peut-être pas de licence.
· Principe : Le mode unicast permet d’implémenter le principe de l’état de vie (Heart Beat) sans devoir utiliser de dialogue broadcast. Les données sont mise à jour via un mode de déclaration de service (service announcements). Le Protocol utilisé est TCP/Point to Point :
ü service announcements Déclaration de service
ü heartbeats État de vies (battement de cœur)
· Principes Unicast :
Connectivité point à point entre les membres du cluster. Optimisation des connexions sockets, car tous les membres ne sont pas connectés en même temps. Les membres du cluster sont divisés en groupes (10 max). Chaque groupe à un nœud leader. Tous les leaders sont reliés entre eux. Tous les nœuds membres du groupe ne sont reliés qu’au leader du groupe.
· Initialisation du cluster.
Lors du démarrage des instances, il y a échange de l’heure de démarrage. L’instance qui a démarré la 1re devient leader. La formation du groupe est limitée à 10 instances, car le trafique d’échange des membres entre groupes se fait par les leaders (surcharge de trafic sur ces instances). Si le leader du groupe disparaît, c’est l’instance du groupe la plus ancienne de prendre le rôle du nouveau leader du groupe. Dans le cas du retour de l’ancien leader (problème réseaux), c’est le nouveau leader qui continue jusqu'à rétablissement de l’ancien via le mécanisme cluster (pas plus de précision sur le sujet !).

UNICAST/MULTICAST
· Fonctionnalité :
Les fonctionnalités Unicast/Multicast sont les mêmes, seule l’implémentation de propagations de l’information est différente. Le trafic Unicast est théoriquement plus fiable, car basé sur TCP mais préférer le mode multicast pour des grands clusters (le multicast étant plus perturbant pour le réseau, mais plus stable, car historique). Les éléments suivants sont les mêmes entre les deux modes :
ü La taille des messages.
ü La taille des flux.
ü Les messages Heartbeats (500 bytes toutes les 10s).
ü Le trafic à l’initialisation.
· Paramétrage :
Les deux modes de cluster peuvent coexister. Pas de possibilité de paramétrage en mode unicast (contrairement au multicast) sauf via un network channel . Le cluster unicast implémente un nouveau protocole cluster-board (non exposé au paramétrage)
Paramétrage :
ü Via la console
ü ClusterMBean.ClusterMessagingMode = ‘unicast’
· Détail de protocol (issue du support) :
Le type de protocole sera vu comme T3, mais encodé de façon différente pour être différencié des autres messages T3.
Le nœud de réception détectera cette spécificité de la requête unicast et court-circuitera la couche de connexion RJVM pour appeler le handler spéciale du cluster.
Les connexions socket établit par le protocole de message unicast ne sera pas partagé par les autres clients T3.
L’implémentation du Protocol unicast est indépendante des containers RMI ou http.
· Monitoring :
Via le mbean UnicastMessagingRuntimeMBean
DiscoveredGroupLeaders | String[] | ["managed1"] | Running group leader names |
Groups | String | {managed1, managed2} | Formatted group list |
LocalGroupLeaderName | String | managed1 | Name of the local group leader |
RemoteGroupsDiscoveredCount | Integer | 0 | Returns the total groups discovered by this server |
TotalGroupsCount | Integer | 1 | Total configured groups - running and not running |
· JMS
WebLogic Server provides an alternative to using multicast to handle cluster messaging and communications. Unicast configuration is much easier because it does not require cross network configuration that multicast requires. Additionally, it reduces potential network errors that can occur from multicast address conflicts.
JMS topics configured for multicasting can access WebLogic clusters configured for unicast because a JMS topic publishes messages on its own multicast address that is independent of the cluster address. However, the following considerations apply:
ü The router hardware configurations that allow unicast clusters may not allow JMS multicast subscribers to work.
ü JMS multicast subscribers need to be in a network hardware configuration that allows multicast accessibility.
· Debug : Pour obtenir des informations de debug, vous pouvez activer l’option suivante dans les paramètres de la JVM de l’instance à analyser.
-Dweblogic.debug.DebugUnicastMessaging=true
Pour l’activité cluster :
-Dweblogic.debug.DebugCluster=true
-Dweblogic.debug.DebugClusterHeartbeats=true
-Dweblogic.debug.DebugClusterFragments=true
Ou
DebugCluster
DebugClusterAnnouncements
DebugFailOver
DebugReplication
DebugReplicationDetails
java weblogic.Admin -url t3://localhost:7001 -username system -password weblogic GET -type ServerDebug -property DebugCluster



ü La répartition des ressources CPU/Mémoire.
ü La centralisation de l’administration.
ü La tolérance aux pannes et à l’indisponibilité de services
ü La scalabilitée de la plate-forme.
Dans le cas où l’on duplique cette architecture pour mettre en place un load-balancer et assurer la disponibilité, c’est l’administration et la scalabilité qui devient problématique, car il faut redéfinir les ressources sur chaque duplication.

DOMAINE MULTI-INSTANCE
Il est donc préférable de mettre en place un environnement multiinstance mono domaine pour la centralisation de l’administration et la scalablité de la solution.
Dans le cas d’un mono-domaine, multiinstance on a le choix du nombre d’instances et du nombre de machines. Cette architecture permet de rajouter en cas de besoins des ressources supplémentaires (accroissement de charge).
Pour l’instance d’administration, il est préférable de la mettre sur une machine différente des machines supportant les instances managées de façon à ne pas être gênées par la charge de production.
Dans le cas ou l’on choisi une architecture avec une seule instance par machine, la problématique sera d’assurer une charge multipliée sur les machines restantes dans le cas d’une panne hardware .
D’autre part, si l’instance d’une machine tombe alors que la machine est toujours disponible, la charge sera quand même routée vers les autres machines inutilement (ressource hardware toujours disponible, mais pas utilisé).

Il est donc préférable d’avoir au moins deux instances par machine pour assurer la disponibilité de la machine en cas de panne instance.

Si le type de machine choisi ne support pas un accroissement de charge en cas de panne hardware, il faudra augmenter le nombre de machines pour atténuer la dégradation.

ü La CPU.
ü La mémoire.
La ressource mémoire est gérée par la JVM. Dans le cas d’une JVM, la mémoire alloué pour l’application est limité en 32 bits à 2 Go. Le seul moyen d’ajouter de la ressource mémoire sur une machine et de rajouter des instances.
Sur la ressource CPU le fait de rajouter des instances ne suffit pas, car la répartition se fait par thread (chaque instance sollicitant de la même façon la CPU). Si l’on souhaite augmenter la capacité de la plate-forme, il faut rajouter des machines.
D’autre pas, dans le cas d’une plate-forme mutualisée (différente application déployée sur la même machine), il est préférable de compartimenter les ressources par instance ou par groupe d’instance. Dans le cas de la mémoire, c’est la JVM qui borne la charge. Dans le cas de la ressource CPU, c’est la machine. Il faut donc mettre en place un mécanisme de virtualisation ‘ pour borner la ressource CPU sur les instances (sur une même machine)

Prenons l’exemple d’un domaine avec 3 instances (A,B,C) et un frontal Apache sur lequel on aura paramétré le plugin. Trois utilisateurs se connectent sur cette plate-forme (u1,u2,u3). Le plug-in est paramétré de façon statique avec l’adresse des 3 instances en cluster.
Détail de paramétrage Apache (httpd.comf)


Au 1er appel du 1er utilisateur u1, le plug-in va détecté que l’utilisateur est nouveau, car ne possédant pas de cookie. Il va choisir une instance dans la liste statique pour le 1er requêtage et prendre la 1er instance (en round robine en cas d’échec).
L’instance qui reçoit la requête détecte que c’est la 1er connexion de l’utilisateur et réalisée un ensemble d’initialisation :
ü Création d’un ID unique pour l’utilisateur
ü Sélection d’une instance secondaire dans le cluster (fonction des groupes de réplications) pour le backup des données
ü Création d’une session utilisateur pour conserver les données utilisateur.
ü Création d’un cookie contenant l’ID utilisateur généré, la référence d’elle-même et de l’instance secondaire.
Après traitement de la requête l’instance retourne le résultat avec le cookie.

Au second requêtage de l’utilisateur u1, le plug-in regarde le contenu du cookie et route l’appel sur l’instance primaire (affinité de session). Lors du requêtage de l’utilisateur u2, le plug-in va prendre la 2eme instance de la liste pour router l’utilisateur sur l’instance B (en round robine).

Ce modèle fonctionne hors cluster. L’ajout d’un cluster introduit une liste dynamique et la réplication des sessions (choix d’une instance secondaire et réplication des données). La liste est construite par les instances du cluster via le Heart Beat.

Quand une instance est défaillante, elle n’émet plus de Heart Beat et les instances voisines après un timeout invalide celle-ci de leur liste. A chaque requêtage utilisateur, cette liste est propagée dans le flux retour à destination du plugin. De cette façon lorsque qu’une instance n’est plus valide le plug-in est renseigné sans devoir la requête (économie du timeout réseau en cas d’échec).
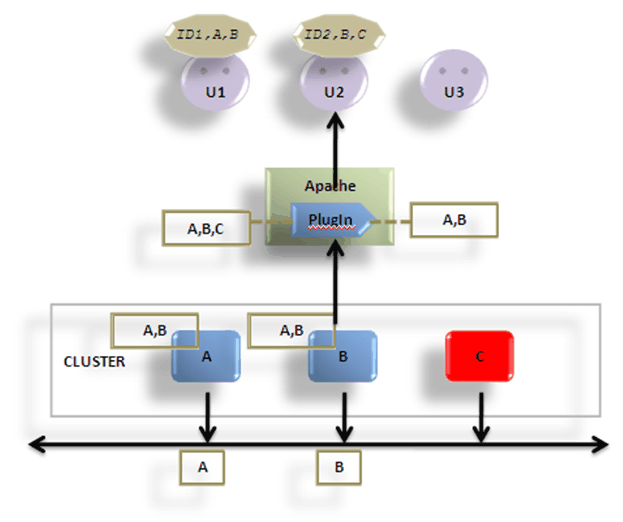
Cela permet également d’ajouter une instance sans devoir la déclarer dans le paramétrage du plugin (scalabilité via la liste dynamique).

Dans le cas de tombée d’une instance sur une plate-forme sur le requêqage de l’utilisateur u1, le plug-in avec la liste dynamique va s’apercevoir que l’instance primaire de cet utilisateur n’est plus disponible et va retrouver dans le cookie l’instance secondaire contenant les données backupées. L’utilisateur est donc routé vers l’instance de backup (il ne s’apercevra pas l’interruption de service).

L’instance secondaire reçoit l’appel de l’utilisateur u1 en failover et restaure ses données pour desservir la requête. Elle va choisir une instance secondaire de backup disponible dans le cluster et se mettre en instance primaire dans le cookie.

Dans le cas d’une plate-forme hors cluster, le plug-in n’a pas l’information de la liste dynamique et utilise sont fichier de configuration (liste statique). Il va essayer de requêter l’instance A avec un timeout et un échec et invalider l’instance de sa liste (temps de timeout dégradant le temps du requêtage utilisateur).

Il va rerouter le flux sur l’instance secondaire, mais sans y retrouve ses données. L’utilisateur perd donc la saisie de ses données.


Le 1er requêtage utilise le paramétrage statique (passé dans le lookup). Sur les autres appels, la liste dynamique rentre en jeux.

Il vaut mieux renseigner l’ensemble des instances associées au cluster dans le paramétrage initial (même remarque que pour la partie HTTP), car si on y place qu’une seule instance et que celle-ci n’est pas disponible sur le 1er appel, le client ne pourra par joindre les autres (pas d’amorçage de la liste dynamique).

Les algorithmes possibles sont plus nombreux et peuvent associés une préférence d’utilisation de ressource déjà crée (connexion). On peut également implémenter son propre algorithme si besoin.
Attention, le cache de l’EJB HOME dans le cas d’optimisation peut poser problème. Valider ce point en faisant des tests de crash recovery.

Lors de l’envoi d’un message sur un des nœuds, l’envoi est loadbalancer sur l’ensemble des instances plutôt que sur l’instance elle-même.

Dans le cas ou il n’y a pas de cluster, il faudra créer autant de file que d’instance et la publication et consommation de message se fera co localisé sur l’instance sans répartition de charge.

Le cluster introduit la notion de Cluster Wide JNDI Tree qui permet lors de la publication d’un objet dans l’arbre JNDI local de le rendre visible sur l’ensemble des nœuds en propageant cette référence sur l’ensemble des arbres JNDI des instances appartenant au cluster. De cette façon, une ressource déclarée est visible de partout et non plus co localisé sur l’instance.

Pour la partie JDBC, il faudra utiliser le mutli datasource ou un paramétrage JDBC sur un cluster Oracle RAC.
Définissez pour les instances a et b
Replication Group : A
Preferred Secondary : B
Définissez pour les instances c et d
Replication Group : B
Preferred Secondary : A

De cette façon, le choix de l’instance de réplication se fera plutôt sur les instances de l’autre machine. Ce paramétrage se fait via la console WLS :
DomaineàServersà{Le Server}àConfigurationàCluster

Extraction de la documentation Weblogic
5-1 Ranking Server Instances for Session Replication
Using these rules, the primary WebLogic Server ranks other members of the cluster and chooses the highest-ranked server to host the secondary session state. For example, the following figure shows replication groups configured for different geographic locations.

In this example, Servers A, B, and C are members of the replication group "Headquarters" and use the preferred secondary replication group "Crosstown." Conversely, Servers X, Y, and Z are members of the "Crosstown" group and use the preferred secondary replication group "Headquarters." Servers A, B, and X reside on the same machine, "sardina."
- Servers Y and Z are most likely to host the replica of this state, since they reside on separate machines and are members of Server A's preferred secondary group.
- Server X holds the next-highest ranking because it is also a member of the preferred replication group (even though it resides on the same machine as the primary.)
- Server C holds the third-highest ranking since it resides on a separate machine but is not a member of the preferred secondary group.
- Server B holds the lowest ranking, because it resides on the same machine as Server A (and could potentially fail along with A if there is a hardware failure) and it is not a member of the preferred secondary group.
To configure a server's membership in a replication group, or to assign a server's preferred secondary replication group, follow the instructions in Configure Replication Groups.
Inscription à :
Publier les commentaires (Atom)


















AUTEUR

- Jean FRANCOIS
- Carrières Sur Sein, Yvelines, France
- Consultant Oracle (Ancien consultant BEA depuis 2001), je m’occupe des expertises sur les produits Oracle : SOCLE (Weblogic, Coherence, JRockit) SOA (Service Bus, SOA Suite, BPM)
MON CV
MAP

CULTURES



LIVRES


















0 commentaires:
Enregistrer un commentaire