mardi 31 mars 2009
Cet article décrit le mécanisme d’allocation de Thread dans Weblogic via les WorkManager. Cette spécificité a été introduite en Weblogic 9 et permet de ne plus se préoccuper de ce paramètre en phase de tuning et déploiement en production. Il ajoute également des fonctionnalités de répartition de ressource et de gestion de crise qui facilite et sécurise l’architecture déployée.
CONTRAINTE
L’ancien mode de gestion de thread imposait un pool de taille fixe utilisé par les applications. On avait la possibilité d’utiliser éventuellement plusieurs pools pour compartimenter un environnement mutualisé (plusieurs applications sur une même instance). Les contraintes de ce mode de fonctionnement étaient :
ü Difficulté de trouver une valeur au pool fonction de la charge de production (risque de sous ou sur utilisation).
ü Obligation de créer d’autres pools de threads pour compartimenter cette ressource (création de threads inutile, car non mutualisé).
ü Mas de moyen de gérer les threads bloqués.
ü Sur dimensionnement de pool dans certains cas d’architecture multi tiers (1 instance portail requêtant 30 instances métier nécessitera 30*nbr threads des instances métiers pour pallier des threads bloqués).
ü Dans une architecture multi tiers, si un des nœuds de la dernière couche est en contention, c’est la totalité des threads des couches en amont qui est absorbée, car mise en attente dans ce nœud.

PRINCIPE
Le pool de Threads est dynamique (ajout/suppression de threads) et unique sur l’instance. Les requêtes mise en attente sont global au pool. Un monitoring est mise en place pour l’auto-tuning et se déclencher toutes les 2 secondes afin d’analyser les données collecter et modifier le nombre de thread nécessaire pour assurer la charge (pas de code natif utilisé, et pas de prise en compte de la charge CPU). L’algorithme prend en compte la valeur courante, le requêtage actuel et l’historisation du trafic pour décider de modifier le nombre de threads. Si historiquement, le moniteur du pool constate un meilleur trafic avec un nombre important de threads, celui-ci va augmenter le nombre de threads, et inversement.
Globalement, WLS priorise les requêtes fonction :
ü Des paramètres d’administration définit.
ü Des métriques Runtime.
ü Temps d’exécution courant.
ü Fréquence des requêtes en entrée.
Des changements sont effectués :
ü Quand le default faire-share est insuffisant.
ü Quand une règle de priorité est définie.
ü Quand l’application nécessite un temps de réponse spécifique.
ü Pour éviter les dead-lock.
Des composants de Work Load Management (WorkManager) gèrent l’allocation et la répartition des Threads sur les applications déployées sur l’instance. Contrairement à l’ancien mode, ces Workmanager sont spécifiques à une application même si elles font référence au Workmanager par défaut (instance différente, mais même paramétrage). Cela permet de suivre la consommation par ressource.

Une politique d’allocation Thread est associée à chaque WorkManager afin de mieux répartir cette ressource sur les applications déployées.
POLITIQUES
Différentes politiques d’allocation de threads sont possibles associées à chaque WorkManager. Ces Workmanager peuvent être associés à une ou plusieurs applications. Deux types de politique sont possibles :
ü Request class : basé sur la priorité (dynamique)
ü Constraints : basé sur des contraintes (statique)
Le Workmanager par défaut et paramètre en faire-share à 50 (toutes les applications sont desservies équitablement). La politique par défaut suffit dans la majorité de cas.
Request Classes
Répartition des ressources associées à des priorités (gestion dynamique).
faire-share-request-class Pourcentage moyen de thread alloué pour desservir la charge sur la ressource (Default : 10 ; Min : 1 ; Max : 1000). Plus la valeur est élevée, plus le nombre de threads dédié sera grand. Ce paramètre est relatif à tous les autres faire-share déclarés sur l’instance. Déclarer deux Workmanager avec 10 et 90 correspond à 10% et 90% des ressources allouées. Un Workmanager déclaré sans faire-share possède un faire faire-share par défaut paramétré à 50.

response-time-request-class Temps de réponse désire (en milliseconde Default : 0). Ce paramètre ne s’applique pas au temps d’exécution de chaque requête, mais plutôt a un temps d’attente à ne pas dépasser fonction de la charge. Le calcul est fait sur chaque thread en faisant la différence des temps passés à l’exécution et les temps passés en file d’attente qui ne doivent pas dépasser le temps moyen demandé. Ce paramètre est relatif aux autres Workmanager déclarés sur l’instance. Deux Workmanager paramétrés avec 1000 et 8000 correspondront à une répartition des requêtes en respectant le ratio 1:8

context-request-class Associer un Workmanager à une information de contexte utilisateur ou groupe.

Constraints
Définir des limitations de ressources sur la capacité (nombre et limite). Ce paramétrage doit être utilisé que dans des cas bien particuliers (il est préférable de laisser faire la réparation par des politiques et l’autotuning). La limitation se fait de façon globale sur l’ensemble d’un même type de WorkManager et non pas par instance de WrokManager.
max-threads-constraint Taille maximum de nombre de thread à utiliser (Default : -1). (On peut associer la valeur de la contrainte à un pool JDBC Œ. Si la valeur du pool JDBC changer, cela affectera directement la valeur de la contrainte).

min-threads-constraint Taille minimum de thread alloué. Cela permet de pré allouer des threads au Workmanager.

Capacity Une fois la capacité atteinte (nombre de requêtes en attente ou en exécution), les requêtes suivantes sont rejetées avec un code retour 503 en HTTP ou RemoteException.

WorkManager
La définition d’un Workmanager va permettre de composer avec ces différentes politiques d’allocation. Plusieurs Workmanager peuvent partager les mêmes contraintes ou politiques.

L’interaction entre ces différentes ressources sur différents Workmanager peut avoir des comportements différents :
ü Dans le cas ou on mélange une politique fair-share et response-time, c’est la seconde qui sera favorisée.
ü Une contrainte minimum peut augmenter l’importance d’une politique faire-share (d’où la préconisation d’utiliser les contraintes de façon précautionneuse).
ü Une contrainte maximum peut empêcher une politique d’atteindre son but.
Default WorkManager
Un WorkManage est généré à chaque déploiement de ressource. Ce WorkManager s’appuie sur un paramétrage. Il existe plusieurs façons de spécifier le paramétrage.
Par défaut toutes les ressources utilisent le paramétrage du default Workmanager positionné en ‘faire share’. On peut surcharger ce paramétrage en créant un Global Workmanager de nom ‘default’.
Plusieurs raisons pour changer le default :
ü Quand le paramétrage par défaut n’est pas suffisant (fair share).
ü Partitionner les applications.
ü Besoins de temps de réponse spécifique.
ü Eviter des deadlocks (positionner une contrainte minimum).
ü Associer la valeur d’un pool JDBC pour allouer les threads en concordance.
On peut également utiliser les paramétrages suivant pour modifier les contraintes du pool de thread sans redéfinir un default WorkManager.
(il est fortement recommandé de modifier le paramètre minimum sous peine d’obtenir des temps dégradés en début de bench)
Paramétrage de JVM
-Dweblogic.threadpool.MinPoolSize=100
-Dweblogic.threadpool.MaxPoolSize=200
config.xml

WLST
managed=”managed1”
cd("/Servers/" + managed)
print "setting attributes for mbean type Server"
set("SelfTuningThreadPoolSizeMin", "100")
set("SelfTuningThreadPoolSizeMax", "200")
Voir la documentation
http://download.oracle.com/docs/cd/E11035_01/wls100/schemaref/security/http.www.bea.com.ns.weblogic.920.domain/types/kerneltype.self-tuning-thread-pool-size-max.html
http://download.oracle.com/docs/cd/E11035_01/wls100/schemaref/security/http.www.bea.com.ns.weblogic.920.domain/types/kerneltype.self-tuning-thread-pool-size-min.html
PARAMETRAGE
Trois types de Workmanager :
ü Default Utilisé par toutes les ressources qui n’ont pas de Workmanager
ü Global Définit via l’administration WLS et visible de toutes les applications.
ü Application-scoped Déclaré dans les descripteurs applicatifs, et spécifiques à l’application.
Le Workmanager peut se déclarer dans le domaine, au niveau de l’application et au niveau module.
ü config.xml création via la console d’administration avec la possibilité d’y associer des applications ou des composants applicatifs.
ü weblogic-application.xml spécification au niveau EAR
ü weblogic-ejb-jar.xml/weblogic.xml spécification au niveau composant
ü weblogic.xml spécification au niveau WebApplication
Avec l’entrée suivante pour les descripteurs J2EE

Et pour le domaine : config.xml

Une fois le Workmanager crée, on peut l’associer à une application avec la primitive ‘dispatch-policy’.
· Dans une WebApplication
weblogic.xml

· Sur un servlet
web.xml

· Dans un EJB
weblogic-ejb-jar.xml

Détail de création à la console WLS pour un Workmanager global

Détail de création à la console WLS pour un Workmanager global

Pour la politique de paramétrage :
ü Préférer l’utilisation de l’application scope pour le paramétrage afin de facilité de portage (pas besoin de paramétrage au niveau domaine).
ü Déclarer des contraintes et politique de classe Global si elles sont utilisées par plusieurs Workmanager.
La prise en compte des déclarations peut se positionner à plusieurs endroits du paramétrage. L’ordre de recherche est le suivant :
ü La recherche se fait en premier dans l’application. Si la ressource est trouvée, elle est prise en compte.
ü Sinon, la recherche se fait au niveau serveur.
ü S’il n’y a pas de définition trouvée, alors un Workmanager par défaut est crée avec une politique faire-share à 50. Une valeur null est positionnée pour les contraintes.
Sur la déclaration du Workmanager avec le
dispatch-policy la recherche se fait de la même façon que présenter précédemment. Dans le cas où le Workmanager n’est pas trouvé dans les policy, un message est généré dans les logs et le Workmanager par défaut est pris pour l’instanciation.ANCIEN MODE
On a la possibilité de revenir à l’ancien mode de gestion de Thread (antérieure à la 9). Pour cela, il suffit de le préciser dans la configuration. Dans ce cas, tous les Workmanager sont remplacés par des pools de threads. La valeur du pool est déduite des contraintes précisées dans les Workmanager. S’il n’y a pas de contrainte définie, la valeur par défaut est prise du default Wrokmanager. Les options contre la surcharge et les contentions ne sont plus disponibles.
Paramètre JAVA
-Dweblogic.Use81StyleExecuteQueues=true
config.xml (préférer ce mode de paramètrage)

MBean
KernelMBean.Use81StyleExecuteQueues to true to disable Self-Tuning
Trace dans les logs en cas d’activation de l’option.
is disabled. An execute queue will be created for
each WorkManager definition.>
Dans le cas où des pools de threads sont déclarés sur une application à porter sur WLS 9/10, il faut la remplacer par un Workmanager spécifique (pas fait automatiquement).
Ce mode peut être utilisé si l’on ne connait pas l’impact du Workmanager sur une application migré (conserver le mode de fonctionnement).
Périodiquement, toutes les 2s un thread de nom IncrementAdvisor est déclenché pour récolter les métriques de performance qui lui permet de mettre en place un auto-tuning. (flag de debug : -Dweblogic.Debug=weblogic.IncrementAdvisor)
Durant la période d’échantillonnage, on calcule le nombre moyen de traitements d’une requête. Toute requête dont le temps de traitement dépasse 7 fois cette moyenne est considérée comme hogged.
L’allocation de thread se décide selon le nombre de thread présent, le throughput actuel et l’historique de la charge appliqué à un algorithme pour décider s’il faut allouer ou retrancher des threads sur le pool.
Une classe spécifique singleton RequestManager gère le pool de thread.
ü Un paramétrage.
ü Un automonitoring.
ü Des codes de sortie d’erreur.
Dans le cas où cette situation n’est pas gérée, la plate-forme peut subir de forte dégradation voir une indisponibilité totale. Prenons le cas d’une architecture avec une couche de présentation (Servlet/JSP) et une couche métier (EJB) dans lequel une instance ne fonctionne pas correctement.

Chaque appel de la partie fonte est load balance sur le cluster EJB, mais tombe régulièrement sur l’instance malade. Malgré la non-réponse de cette instance, les requêtes sont mises en attente d’une hypothétique prise en compte. Donc chaque requête client utilisant un thread de la partie front va être mise en attente lors du requêtage du nœud défaillant de la partie back.

Au fur et à mesure des requêtages, c’est l’ensemble des utilisateurs qui vont être bloqué sur la partie front à cause d’un nœud de la partie back alors que le cluster EJB possède encore des instances valides.

En indiquant à l’instance malade qu’il ne faut plus accepté de requêtage en cas de dysfonctionnement, les requâtage en erreur seront rejoués sur les instances valides de la partie back.

De cette façon, on évite à la plate-forme de s’effondrer sur une défaillance d’un de ces éléments. Pour réaliser cela, Weblogic propose les mécanismes d’Overload Portection.
Configuration Weblogic
Dans certains cas de surcharge de capacité, l’acceptation de nouvelle requête peut entrainer une dégradation du système. Il faut donc sous certaines conditions refuser la charge subite en paramétrant Weblogic. L’objectif de ce paramétrage est donc de détecter ces états instables et d’y apporter une action corrective (si possible). Une instance est en difficulté quand :
ü La limite de requêtage du pool de thread est atteinte.
ü La limite du nombre de sessions http est atteinte.
ü La capacité mémoire de la JVM est atteinte (OutOfMemory Exception)
ü Des threads sont bloqués
Requêtes
Quand le nombre de requêtes en attente atteint son maximum, les requêtes sont rejetées (sauf pour les requêtes d’administration sur channel dédié) :
ü Pour les Web application
ü Les requêtes RMI (non transactionnel) en commençant par les requêtes de faible priorité (faible faire-share).
Si la surcharge persiste, les rejets sont propagés aux autres requêtes de plus haute priorité (excepté aux transactions JMS).
On peut repousser la limite par défaut qui est paramétré à 65536 via la console d’administration, ou pour une granularité plus fine utiliser le paramétrage des WorkManager.
Environments à Servers à Threads and select an execute queue

HTTP Session
On peut limiter le nombre de sessions actives :
ü En cas de problème de sur capacité mémoire.
ü Restriction d’accès sur un site sous dimensionné.
ü Compartimentation des ressources sur une instance mutualisée (par utilisateur)
Une fois la limité atteinte, Weblogic rejette les connexions de nouveaux utilisateurs sur l’instance.
ü Dans le cas d’un cluster, le plug-in redirige l’appel refusé sur une autre instance du cluster.
ü Dans le cas d’une instance non clustérisé, on peut rediriger l’appel sur une autre instance (à spécifier sur le serveur HTTP par rapport à un retour d’erreur 503 levé par le Servlet Container ou applicativement sur la levée d’exception de type SessionCreationException).
Le paramétrage se fait dans le weblogic.xml

ü Une sur consommation mémoire (session trop grande) associée à une charge (dépassement de la capacité établie sur l’instance).
ü Une fuite mémoire (problème applicatif à corriger).
On peut le paramétrer via la console d’administration WLS ou en entrant les lignes suivantes dans le config.xml.

config.xml

Une fois l’alerte levée, on a la possibilité de rendre le Workmanager inactif rendant l’application indisponible, ou d’arrêter l’instance (il n’y a pas de kill de thread). Dans le cas ou l’instance est arrêté, Il faut redémarrer celle-ci pour rétablir la situation. La relance peut s’effectuer via le node manager (avec un retry paramétrable).
· Global
Un paramétrage global peut être appliqué via la console Weblogic est valide pour le WorkManager par défaut.
EnvironnementàServersàConfigurationàOverload

· Local
On peut appliquer ce paramètre à un Workmanager qu’on aura déclaré spécifiquement pour une application via la console Weblogic. Il faudra rajouter dans le descripteur JEE de l’application l’entrée suivant :
weblogic.xml

ü La capacité des Workmanager est dépassée.
ü Une alerte mémoire est remontée.
Exit CODE
Quand processus Weblogic s’arrête, il retourne code retour qui peut être utilisé par les scriptes shell ou les agents afin de décider s’il faut redémarrer l’instance.

See “WebLogic Server Exit Codes and Restarting After Failure” in Managing Server Startup and Shutdown
For more information, see the attributes of the OverloadProtectionMBean
-Dweblogic.Debug=
Avec comme valeur
weblogic.IncrementAdvisor | Logs self-tuning data every 2 seconds |
weblogic.workmanagercollection | Logs WorkManager information during deployment |
weblogic.wmglobalcomponentsfactory | Logs information about global work managers |
weblogic.stuckthreadmanager | Logs information about stuck thread handling |
${instance}àRuntimeServiceMBeanàServerRuntimeàThreadPoolRuntimeMBean
Information sur l’activité du pool
CompletedRequestCount | Nombre de requêtage réalise depuis le démarrage de l’instance (prendre la valeur d’avant pour calculer le throughtput) | 141415 |
ExecuteThreadIdleCount | Nombre de threads inoccupé (libre) | 0 |
ExecuteThreadTotalCount | Nombre total de threads dans le pool | 15 |
HoggingThreadCount | Nombre de thread utilisé par des requêtes trop lente | 5 |
MinThreadsConstraintsCompleted | 14126 | |
MinThreadsConstraintsPending | 0 | |
PendingUserRequestCount | Nombre de requête utilisateur en attente sur le pool de thread du serveur | 0 |
QueueLength | File d’attente des requêtes en utilisateur | 0 |
SharedCapacityForWorkManagers | 65536 | |
StandbyThreadCount | Nombre de threads plus utilisé et mise en attente (réserve pour éviter une trop grande activité de création de threads) | 9 |
Throughput | 3.5 |
Le nombre de actif = nombre de inoccupé + nombre de threads occupé
${instance}àRuntimeServiceMBeanàServerRuntimeà${instance}àApplicationRuntimesà${application}àWorkManagerRuntimesà${nom du workmanager}
Activité de chaque workmanager
ApplicationName | String | TestFreez |
CompletedRequests | Long | 0 |
ModuleName | String | null |
PendingRequests | Integer | 0 |
StuckThreadCount | Integer | 0 |
CompletedCount | Long | 0 |
DeltaFirst | Long | 1086 |
DeltaRepeat | Long | 1086 |
Interval | Double | -1.0 |
MyLast | Long | 0 |
PendingRequestCount | Integer | 0 |
RequestClassType | String | fairshare |
ThreadUseSquares | Long | 0 |
TotalThreadUse | Long | 0 |
VirtualTimeIncrement | Long | 0 |
DeferredRequests | Integer | 0 |
ExecutingRequests | Integer | 0 |
CompletedRequests | Long | 0 |
CurrentWaitTime | Long | 0 |
ExecutingRequests | Integer | 0 |
MaxWaitTime | Long | 0 |
MustRunCount | Integer | 0 |
OutOfOrderExecutionCount | Long | 0 |
PendingRequests | Integer | 0 |

STARTEGIE
activeThreadCount= ExecuteThreadTotalCount-(ExecuteThreadIdleCount+StandbyThreadCount)
- ACTIVE: The thread is active and is executing work or is ready to pick up work when it arrives.
- STANDBY: The thread is removed from the active thread pool and is not picking up work. It can still execute work from the minimum threads constraint work set if the constraint is not met. The self-tuning implementation has removed this thread from the active pool since it is not improving throughput. It can be moved back into the active thread pool if needed later.
- STUCK: A thread is stuck executing work for more than the configured stuck thread interval. The thread could be stuck due to a deadlock or a slow responding back end connection.
Un paramètre de JVM a été créé spécifiquement afin de déclarer une valeur minimale au workmanager default.
-Dweblogic.threadpool.MinPoolSize=
min-threads-constraint
There are special situations where two servers can deadlock if a WorkManager does not get a minimum number of threads. For example, consider when Server A makes an EJB call to Server B, and Server B in turn makes a callback to Server A as a part of the same request processing. In this case, we know that until Server A responds to the callback from Server B, its original request to Server B will not get serviced. This scenario can be addressed in two ways. Configuring a WorkManager in Server A with a high fair share for callback requests from Server B will ensure that those requests get higher priority than new requests arriving at Server A from clients. In addition, adding a minimum threads constraint clause to the WorkManager will ensure that at least some threads in Server A will be able to pick up callback requests from Server B even when all the threads are busy or deadlocked.

Dualité de ressource
Deux pools MDB embarquent un connecteur d’accès à une ressource (Moteur C) externe limité en capacité de connexion (50). Le première pool envoi les requêtes et le second récupère la réponse (1 envoi = 1 réponse asynchrone).
Dans le cas où on dimensionne les pools MDB de la même valeur que les ressources C, il peut y avoir saturation de cette ressource.

Une solution et de diviser la taille des pools par 2 afin de ne pas dépasser la somme totale des ressources C. Le problème est qu’en phase nominale, seules 25 requêtes seront possibles.

Pour que les deux pools MDB ne dépassent pas la taille limite de 50 requêtage en conservant la totalité des ressources C, on peut utiliser un WorkManager dédié à ces pools paramétrés à la même valeur que la ressource C, en conservant la taille des pools MDB à la valeur de la ressource C.

La définition de ce WorkManager peut se faire dans les descripteurs J2EE des MDB.
Attachement du MDB interrogation au WorkManager
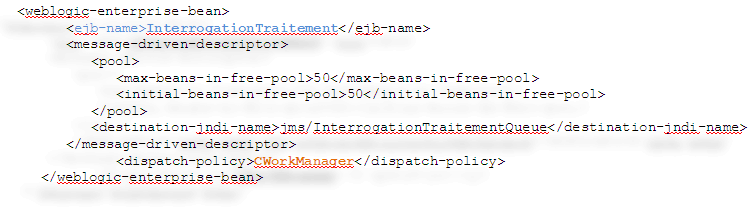
Attachement du MDB notification au WorkManager

Définition du WorkManager

Inscription à :
Publier les commentaires (Atom)


















AUTEUR

- Jean FRANCOIS
- Carrières Sur Sein, Yvelines, France
- Consultant Oracle (Ancien consultant BEA depuis 2001), je m’occupe des expertises sur les produits Oracle : SOCLE (Weblogic, Coherence, JRockit) SOA (Service Bus, SOA Suite, BPM)
MON CV
MAP

CULTURES



LIVRES


















0 commentaires:
Enregistrer un commentaire